Neuronové sítě, jak vlastně fungují?
Leccos je dnes ovlivněno neuronovými sítěmi, naše aplikace pro komunikaci, různé algoritmy personalizace, které nám dokážou kdykoliv doporučit to co zrovna hledáme, ale i v lékařství, kde neuronové sítě úspěšně detekují nádory a další rakovinotvorné onemocnění. Ale jak tyto algoritmy fungují? A jak to že tak silně ovlivnily směřování moderního světa?
Proč je vůbec máme?
S postupem vývoje počítačů (na které jsem tady také měl článek), se i začaly ztěžovat úlohy které měly samotné počítače řešit. Např. jak chceme takový počítač naučit předpovídat cenu zlata tím že analyzuje předchozí roky? Toto s naším „hloupým“ počítačem nesvedeme, pokud teda nepoužijeme statistiku. Pojďme si ale nejdříve ukázat nějaké rozdělení těchto algoritmů
Machine learning, Deep learning a Reinforcement learning
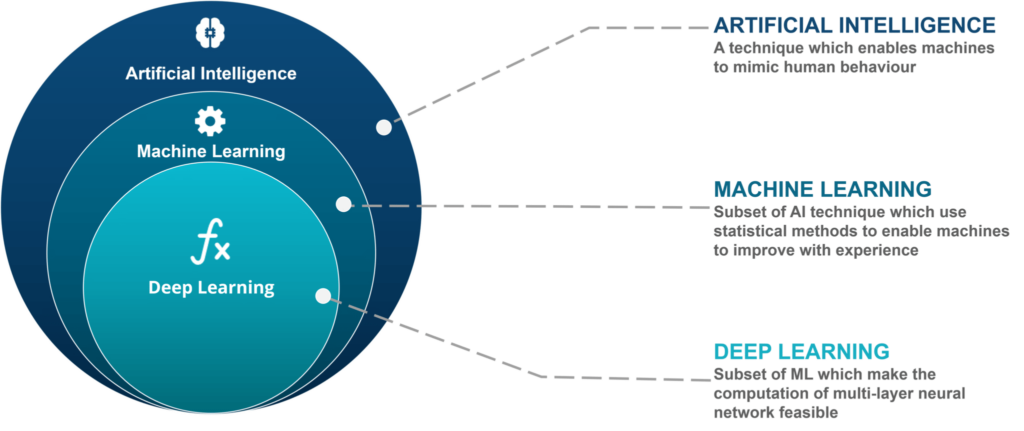
Samotný proces tohoto „učení“, se dělí do několik částí, a to: extrakce příznaků, následné vytvoření testovací a trénovacího a testovacího datasetu, natrénování algoritmu a otestování jak moc efektivní je. Dataset je množina dat ze kterých se algoritmus učí, data obsahují input a output (který by měl na trénovacích datech vyhodit)
Deep learning
- Potřebuje mnohem větší počet prvků v datasetu
- Algoritmus se dokáže sám učit
- Základním prvkem jsou neuronové sítě, které se skládají z neuronů
- Dokáže mnohem lépe „pochopit“ data
- Hodně náchylná k overfittování*
- Dokáže řešit problémy klasifikace, regrese, clusteringu a dimensionality reduction
- Díky náročnému trénování potřebujete GPU
Machine learning
- Může se trénovat i na menších datasetech
- Potřebuje lehkou korekturu průběhu trénování od člověka
- Složeny ze statistických metod, společně s automatizací těchto metod
- Nedokáže tak dobře „pochopit“ data
- Hodně náchylná k underfittování*
- Dokáže řešit problémy klasifikace, regrese, clusteringu a redukcí dimenze
- Zde vám bohatě stačí CPU
* tyto problémy vysvětlím v dalším článku
Reinforcement learning
Reinforcement learning (v češtině zpětnovazební učení) je speciální druh trénování umělé inteligence. Tomuto tématu se budu věnovat v jiném článku, protože věřím že zrovna tento speciální případ učení si to zaslouží, takže zde pouze napíšu stručný úvod.
Tento styl trénování je inspirován psychologií, právě díky tomu, že člověk za svůj život dostane hodně kritiky (ať už objektivní nebo ne), která dokáže ovlivnit jeho chování. Na podobném principu funguje zpětnovazební učení, dáme do jakéhosi virtuálního prostředí náš algoritmus, a následně ho necháme aby začal dělat několik náhodných rozhodnutí, která mu buď dají pozitivní body, nebo negativní body. Díky tomuto dokážeme modelovat vývoj dostatečně inteligentního organismu
Supervised vs Unsupervised learning
Supervised
Supervised learning (v češtině učení s učitelem) je v případě problému klasifikace nebo regrese. Každý prvek v datasetu má předem daný vstup a výstup aby se dokázal algoritmus natrénovat na těchto prvcích a následně dělat vlastní klasifikace/predikce. Většinou jsou efektivnější než Unsupervised metody, ale zase potřebují korekturu od člověka.
Unsupervised
Unsupervised learning (v češtině učení bez učitele) je v případě problému clusteringu, redukcí dimenze. Zde dáme algoritmu data bez žádných dalších specifikacích, přičemž algoritmus musí sám zjistit vztahy mezi danými hodnotami. Tyto algoritmy nevyžadují korekturu od člověka, ale zase nejsou tolik efektivní.
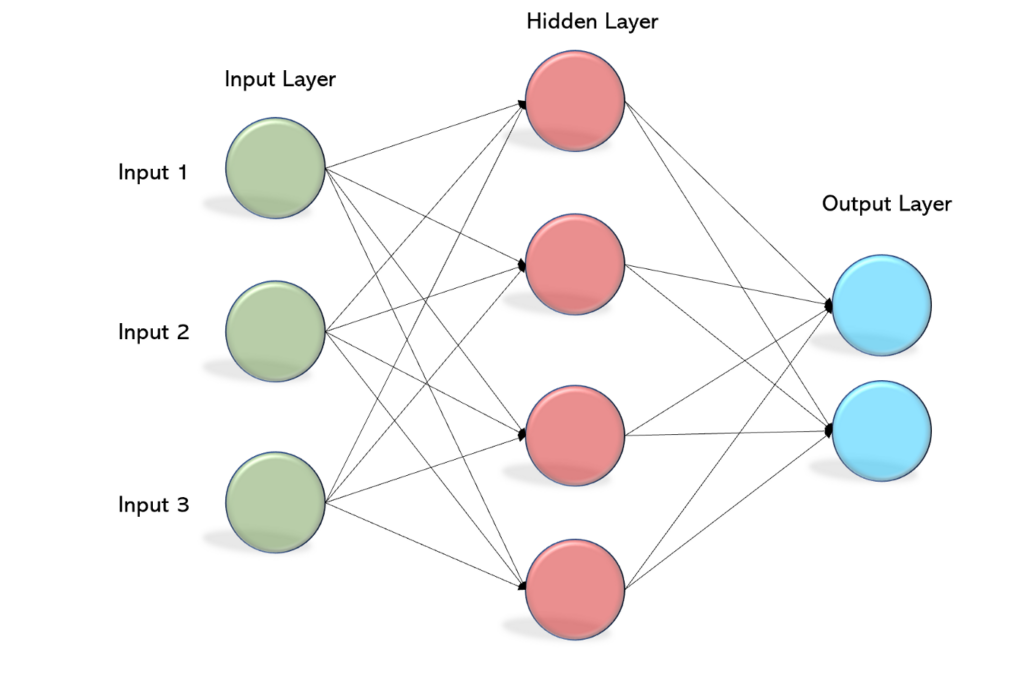
A teď k Neuronové síti samotné…

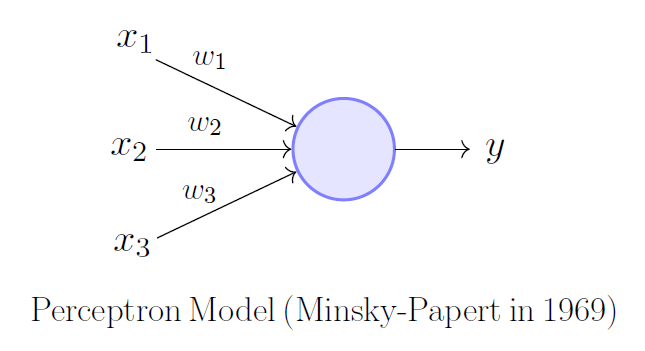
Základní stavební prvek neuronové sítě je neuron (v obrázku je Perceptron, avšak princip je stejný), neurony jsou provázané dohromady do neuronové sítě. Ve vstupu má neuron předchozí výstupy neuronů